
In the Bitbucket team, we believe containerization is the future of continuous integration and deployment. Running your software in containers brings consistency and predictability all the way from your development environment, through your CI/CD pipeline out to production.
To help smooth the path for container-based development, I wanted to reflect back on a set of improvements we’ve made to Docker support in Pipelines over the past few months, which bring speed and new capabilities to your build process. With these improvements, Bitbucket Pipelines is now the leading choice for building and shipping Docker-enabled applications in the cloud.
Pipelines is Docker all the way down
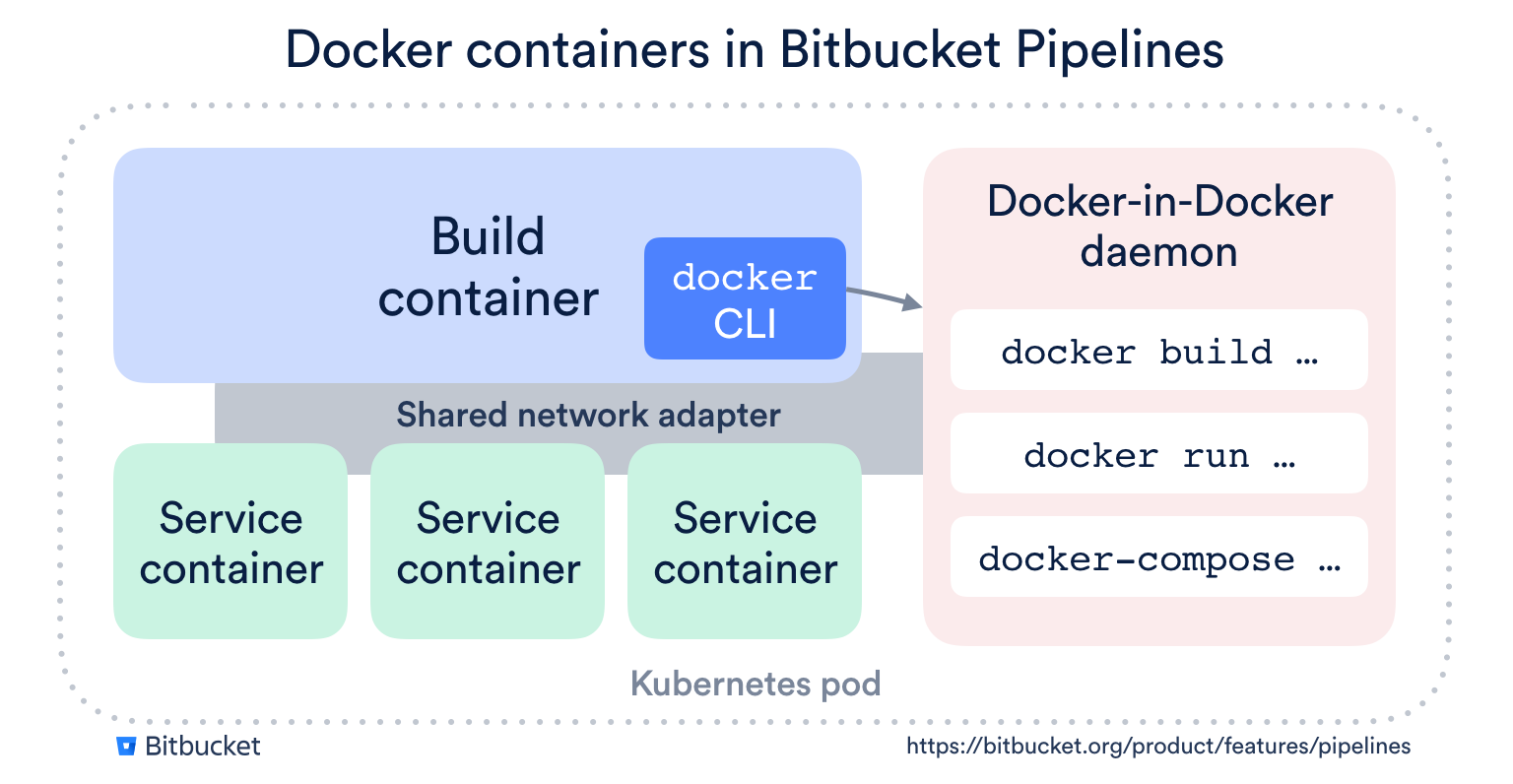
Docker applications will feel at home on Bitbucket Pipelines because everything in Pipelines is built on Docker:
- Your build environment is a Docker image. No pre-baked VMs with slow startup and six-month-old dependencies. As soon as a new release of your favorite platform hits Docker Hub, you can use it in Pipelines.
- The services your build uses (databases, etc) are just Docker images. They share a network interface with your build container, so you don’t even need to worry about port mapping.
- Built-in support for Docker build, tag and push. Just enable it in your build, and we’ll run a Docker-in-Docker daemon and provide the docker command-line tool so it works out of the box.
Here’s a diagram showing how this all fits together:
But this is just the beginning with Pipelines. From this solid foundation, we’ve been able to layer on some great features that will make your Docker builds even faster and more powerful.
Lightning fast builds thanks to comprehensive Docker caching
"My build is too fast", said no developer, ever. We've built several levels of caching into Pipelines for Docker users, so your Docker builds can run as fast in the cloud as they do locally:
- Image caching will automatically apply to all public Docker Hub images used in your build.
- Layer caching will include all images and intermediate layers used by the Docker-in-Docker daemon that powers your Docker builds on Pipelines. Enable this by adding the docker cache to your Pipelines steps, as shown below.
- Custom caches can be defined in your Pipelines configuration, allowing you to cache the things that we miss. (These are flexible enough that we actually implemented layer caching in this way.)
Among customers who have enabled Docker layer caching, we’ve seen 80% of repositories shave off more than 30% of their uncached build time – and almost half (49%) have cut more than 50% off their uncached build time. These dramatic reductions will save real time in your team's daily feedback loop.
Docker builds up to 7GB with configurable memory limits
With two improvements that enable bigger and more complex builds, you can now use up to 7GB for building and running Docker containers in Pipelines:
- Large builds support allows you to allocate a total of 8GB of memory to your build (up from 4GB). Double memory costs you double the build minutes, so we recommend using it only where you need it.
- Configurable memory for services allows you to specify how you want to this memory allocated. We require 1 GB for your build image and our overheads, so the 7GB remainder can be allocated to service containers or to your own Docker containers.
Here’s an example of configuring 7GB for Docker operations in bitbucket-pipelines.yml:
pipelines:
default:
- step:
size: 2x # double memory (8GB) for this step
script:
- ... # do some memory-intensive docker stuff
services:
- docker
caches:
- docker
definitions:
services:
docker:
memory: 7168
This additional memory might make you wonder why you wouldn’t just spin up your entire application in Pipelines for some delicious integration testing. Which leads us on to…
Spin up your entire application with docker-compose
If you’re using Docker heavily, you probably have a bunch of docker-compose YAML files to kick off your application in a variety of configurations. With the Docker-in-Docker daemon in Pipelines, you can now use docker-compose to spin up your entire application for testing.
Below is an example of using docker-compose with a 7GB memory allocation to spin up a set of services and test them out.
Note that this example has a few extra commands to install the mysql client and docker-compose binaries that aren’t necessary in a real build scenario, where you would bake your dependencies into a custom Docker image for your build environment.
pipelines:
default:
- step:
size: 2x # double memory (8GB) for this step
services:
- docker
caches:
- docker
script:
- apt-get update -y && apt-get install -y mysql-client
- curl -L https://github.com/docker/compose/releases/download/1.19.0/docker-compose-Linux-x86_64 -o /usr/local/bin/docker-compose
- chmod +x /usr/local/bin/docker-compose
- docker-compose up -d
- docker-compose ps
- ./wait-for-container.sh build_mysql_1
- echo 'select 1' |
mysql -h 127.0.0.1 -u root -psecret testdb
- docker-compose logs mysql
definitions:
services:
docker:
memory: 7168
This example uses this docker-compose.yml, and wait-for-container.sh – a small shell script to poll the Docker health check and wait for a container to start.
If you want a better look at how this docker-compose example fits together, check out the docker branch in my demo repository.
Try Bitbucket for your next Docker-powered project
If your team is big into Docker, you now have a list of great reasons to try out Bitbucket for your next project.
Try Bitbucket today, and enjoy the benefits of a CI/CD solution purpose-built for Docker.


